
Windows用のPDF Extractor SDKソフトウェア開発者:PDFからテキスト、PDFからXML、PDFからの画像、PDF情報の読み込み、PDFをCSV for Excelでご覧いただけます。
Bytescout PDF Extractor SDKは、追加のソフトウェアを必要とせずに、PDF、XML、PDF、CSV、PDFから画像を抽出、.NETおよびActiveXインターフェイスでPDFファイルに関する情報を抽出することができます。
利点:
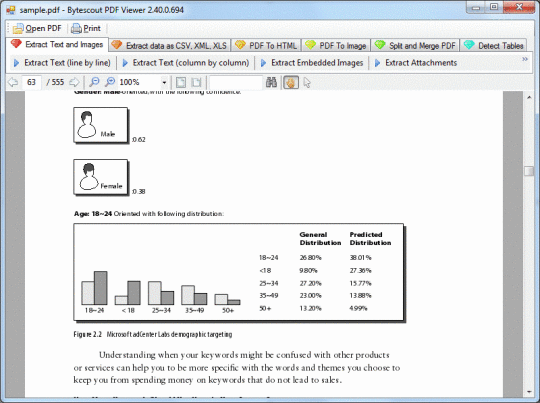
PDFをプレーンテキストに変換します(PDF形式の新聞を変換する場合は列をたどることができます)。
指定された矩形からセルを読み込むことにより、PDFの表をExcel(CSV)に変換します。
PDF内のテーブルをXMLファイルに変換します。
PDFファイルのメタデータ(タイトル、著者、説明)を抽出し、ファイルに関するその他の情報を取得します(ページ数、暗号化されているかどうか)。
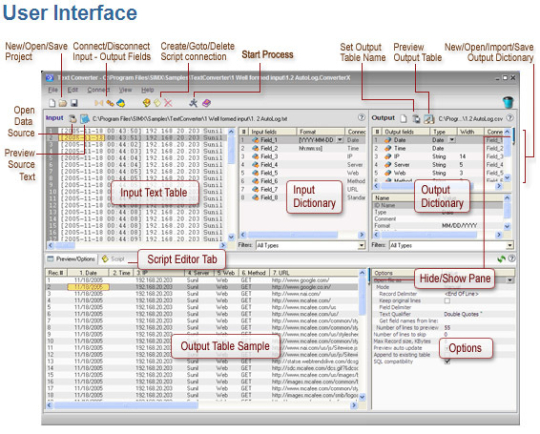
PDFドキュメントから埋め込み画像を抽出します(ASP.NET、VB.NET、C#、VB6、VBScript)。
DocumentMergerとDocumentSplitterのインターフェイスとクラスを使用してPDFドキュメントをマージしたり分割したりできます。
Adobe Readerまたはその他のPDFリーダーソフトウェアをインストールする必要はありません。
.NETとActiveXのインターフェイスを提供します。
100%マネージドC#コードで作成されています。
このリリースの新機能:
バージョン9.0.0.3079:抽出したコンテンツをフォント名、フォントサイズ、色でフィルタリングする機能を追加。
OCRエンジンを最新バージョンに更新しました。 'tessdata'フォルダーから言語ファイルを更新します。
バージョン8.7.0.2980の新機能:
抽出されたテキストの抽出、行のグループ化、表形式のデータ、パフォーマンス、XFAフォーム抽出、TableDetector、固定PDF解析の問題を改善しました。フォント名、フォントサイズ、および色によるコンテンツ。
OCRエンジンを最新バージョンに更新しました。 'tessdata'フォルダーから言語ファイルを更新します。
バージョン8.6.0.2911の新機能:
抽出されたテキストの抽出、表形式データの行グループ化、パフォーマンス、XFAフォーム抽出、TableDetector、固定PDF解析の問題。フォント名、フォントサイズ、および色によるコンテンツ。
OCRエンジンを最新バージョンに更新しました。 'tessdata'フォルダーから言語ファイルを更新します。
バージョン8.2.0.2699の新機能:
バージョン8.2.0.2699の改善されたテキスト抽出、表形式のデータの行グループ、パフォーマンス、XFAフォームの抽出、TableDetectorの固定PDF解析の問題。
バージョン8.0.0.2528の新機能:
抽出したコンテンツをフォント名、フォントサイズ、色でフィルタリングしました。
OCRエンジンを最新バージョンに更新しました。 "tessdata"フォルダーから言語ファイルを更新します。
改善されたテキスト抽出。
表形式データの行グループを改善しました。
パフォーマンスを向上させた。
XFAフォームの抽出が改善されました。
改良されたTableDetector。
PDF解析の問題を修正しました。
固定JBIG画像の復号化。
ImageExtractor:固定ページ毎の画像抽出。
MultimediaExtractor:埋め込みMPEGオーディオの固定抽出。
TextExtractor:固定された非動作のRemoveHyphenationプロパティ。
その他のマイナーな改善とバグ修正
バージョン7.0.0.2474の新機能:
バージョン7.0.0.2474:
新しいDocumentPrinterユーティリティークラスが追加され、PDF文書をサイレントに印刷できるようになりました(ユーザーダイアログなし)
新しいJSONExtractorクラスが追加されました
生成されたファイルの出力フォルダを指定できるDocumentSplitter.Split()メソッドのオーバーライドが追加されました。
DocumentSplitterのマルチスレッドバグを修正
tableDetectorはSetExtractionArea()メソッドで設定された抽出領域を参照するようになりました
抽出クラスの新しいプロパティ:ExtractionColumns - 検出された列の座標を含む。 CustomExtractionColumns - 列の検出を無効にすることができます。
GetPageRect *メソッドはページローテーションを考慮しませんでした。
インストーラのバグが修正され、以前のインストールの一部のファイルが更新を妨害していました
登録チェックを修正しました。今度はライブラリが例外をスローしませんが、間違ったRegistrationNameとRegistrationKeyを入力しなかった場合、デモモードで動作します
PDFマルチツール:「PDFドキュメントを開く」ボタンに最近のドキュメントリストを追加
PDF Multitool:選択範囲のサイズ変更が可能
PDF Multitool:Extract JSON機能の追加
PDF Multitool:表検出器UIの改善
PDF Multitool:フォントのレンダリング品質を大幅に改善
PDF Multitool:コンテキストメニューにデバッグオプション "検出された抽出カラムを表示"を追加し、検出されたカラムを現在のページに表示します。現在表示されているページに対して抽出を実行した後にのみ表示されます。
PDF Multitool:32ビットWindowsでのフォントのレンダリングの問題を修正
その他のマイナーな改善とバグ修正
バージョン6.30.0.2421の新機能:
バージョン6.30.0.2421:
2つのPDFドキュメントのテキストを比較してレポートを生成できるようにする、TextComparerユーティリティクラス(.NET 4.0アセンブリのみで使用可能)を追加しました。
ICCカラープロファイルのサポートが改善されました。
埋め込みフォントの処理を実装しました。
AttachmentExtractorを改善しました。
XMLExtractor.SaveXMLToStream()メソッドを修正しました。
OCRCacheMode.WholePageオプションを使用すると、抽出されたテキストの複製が修正されました。
その他のバグの修正と改善。
バージョン6.20.2354の新機能:
バージョン6.20.2354:
PDFをテキストに、PDFをCSVに、PDF To XML機能を改善
新しい抽出ビデオ、抽出オーディオの例
CSVおよびXMLエクストラクタでは、空の列があるテーブルのサポートが改善されました。
PDFからビデオとオーディオを抽出する新しいMultimediaExtractor
新しいプロパティPageDataCaching
新しい "MemoryCareProcessingOfHugeFiles"の例
既に破棄されたページを破棄しようとするとnull null例外が修正される
XLSExtractor:フォントサポートを向上
SkipInvisibleTextはクリップされたテキストをスキップします(これは表示されません)
テキスト出力レンダリングの改善
XFDF Extractor:チェックボックスのサポートが追加されました
より多くのサブフォーマットをサポートするように画像出力が改善されました
Unicodeテキスト処理の改善
バージョン6.11.2149の新機能:
バージョン6.11.2149:
バッチ処理サンプルは、Reset()メソッドの使用を示すように更新されました。
ページ抽出用にC ++ソースコードサンプルが追加されました。
DocumentMergerはMerge2(inputfile1、inputfile2、outputfile)メソッドを追加して2つのファイルをマージします
XLS Extractorマイナーバグ修正
PDF Multitoolでは、テキスト、画像、ベクターレイヤーの有効/無効、テキスト抽出の高度な設定の追加が可能になりました
XML、CSV、表抽出により、列内にemtpryセルを持つ表のサポートが向上
.ExtractShadowLikeTextプロパティが改善されました。シャドウライクなテキストのフィルタリングが改善されました。
バージョン6.10.2136の新機能:
バージョン6.10.2136:
PDFからXMLへ、PDFからCSVへ、PDFからテキストへの機能の改善
PDF To XLSコマンドラインサンプルを追加(vbscriptに基づいて)
PDF To HTML SDKは、新しい.DetectHyperLinksプロパティ(デフォルトではTRUE)を追加して、テキスト内の自動リンク検出を有効/無効にします
PDFを検索可能なPDFファイルに変換する新しいSearchablePDFMaker(PROライセンスで利用可能)
エクストラクタの新しいプロパティ:CFGファイルのConsiderFontNames、ConsiderFontSizes、ConsiderFontColors、ConsiderVerticalBorders
ヘッダー列の検出(AutoAlighHeaderToColumns = trueの場合)が改善されました
行を段落にマージする方法を制御する.DetectLinesInsteadOfParagraphsを新しい.LineGroupingModeに置き換えました。
重要! PDF To XMLは、テキストオブジェクトの誤ったY座標の長時間の問題を修正しました(左上ではなく左下を指していました)
.TableXMinIntersectionRequiredInPercentsおよび.TableYMinIntersectionRequiredInPercentsプロパティが追加されました。
C ++ソースコードサンプルが追加されました
PreserveFormatting = trueモードで空の列が見つからないとXML Extractorで修正される
一部のPDFファイルの色のマイナーな修正
追加された複数のOCR言語のサポート
PDF Multitool GUI:TXT、CSV、XML、およびラスターレンダラーダイアログにクリップボードにコピーボタンを追加する
XLSExtractor:ページごとに別々のワークシートの生成を有効/無効にするPageToWorksheetプロパティを追加します。
新しい.TextEncodingCodePageプロパティ
PDFViewerControl:ValidateContextMenuを追加して、ユーザがコンテキストメニューにカスタム項目を追加できるようにする
PDFビューアコントロール:プロパティの追加ShowTextObjects、ShowImageObjects、ShowVectorObjects
XMLExtractorは認識されたテキストに「OCRConfidence」属性を追加するようになりました
PDF / Aチェック機能(ベータ版)
元のレイアウトに従ってコントロールとテキストのチェックとアラインメントを改善します。この問題は、解析中のコントロールのY座標の移動によって発生しました。これは間違っていました。正しい方法は移動することです...
XML Extractorが更新されました:チェックボックスとテキストフィールドのCONTROLタグが生成されるようになりました
現在のディレクトリから一時ディレクトリに変更
チェックボックス、ラジオボックス、エディットボックス、コンボボックスがよりよくサポートされています
部分信頼者を許可
バージョン5.80.1781の新機能:
バージョン5.80.1781:
PDFからXMLへ、PDFからCSVへ、PDFからテキストへの機能更新
OCRModeは9つのモードを提供するようになりました
.DetectLineInsteadOfParagraphがより良く機能するようになりました。表のセルに複数行のテキストをキャプチャするには、Falseに設定します。
改善されたPDFコントロールサポート
FDFおよびXFDFデータ抽出
バージョン5.10.1747の新機能:
バージョン5.10.1747:
PDFからXMLへ、PDFからCSVへ、PDFからテキストへの機能の改善
テキストコントロールからのテキスト抽出をサポートするようになりました
XMLエクストラクタは、フォントスタイル、サイズ、名前、テキスト座標をタグに追加するようになりました
OCR使用のためのASP.NETサンプルが追加されました
"tessdata"フォルダの場所を指定する新しいプロパティOCRLanguageDataFolder
PDFファイルの改善されたサポート
回転テキストのサポートを改善
更新されたソースコードサンプル
更新されたドキュメント
マイナーな改善と修正
バージョン5.00.1626の新機能:
バージョン5.00.1626:
OCR(画像からのテキスト)機能が追加されました:埋め込み画像からテキストを抽出し、破損したテキストを修復できるようになりました
いくつかの設定で最後の列が見つからないCSVとXML抽出ツールで修正された問題
破損したPDFファイルのサポート強化
単語マッチングモードを使用した複数行の検索テキスト検索がサポートされるようになりました
ハイフンで、異なる行でテキストを検索することができます:新しいソースコードサンプルを見るハイフンでテキストを検索する
RTL言語を自動的に検出するための新しいプロパティ.RTLTextAutoDetectionEnabled(デフォルトはfalse)
PDFビューアのGUIデモが改善されました
マイナーな改善と修正
要件:
.NET Framework 2.0以上

コメントが見つかりません